物理测试暴击AI圈,DeepSeek R1稳超o1、Claude,我们已进入RL黄金时代
- 国际
- 2025-01-26 01:40:12
- 21
专题:DeepSeek为何能震动全球AI圈
来源:机器之心
我们都没预料到,AI 领域的 2025 年是这样开始的。
DeepSeek R1 真是太厉害了!
最近,‘神秘的东方力量’DeepSeek 正在‘硬控’硅谷。
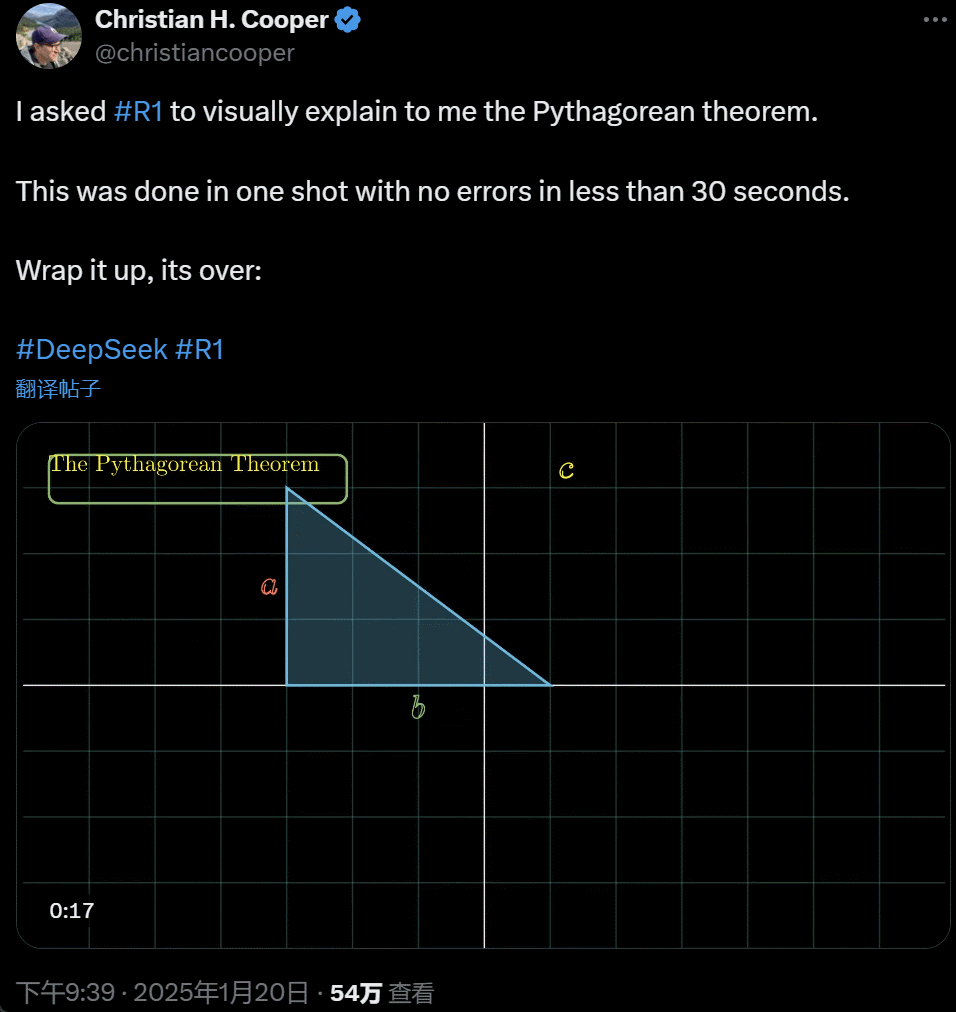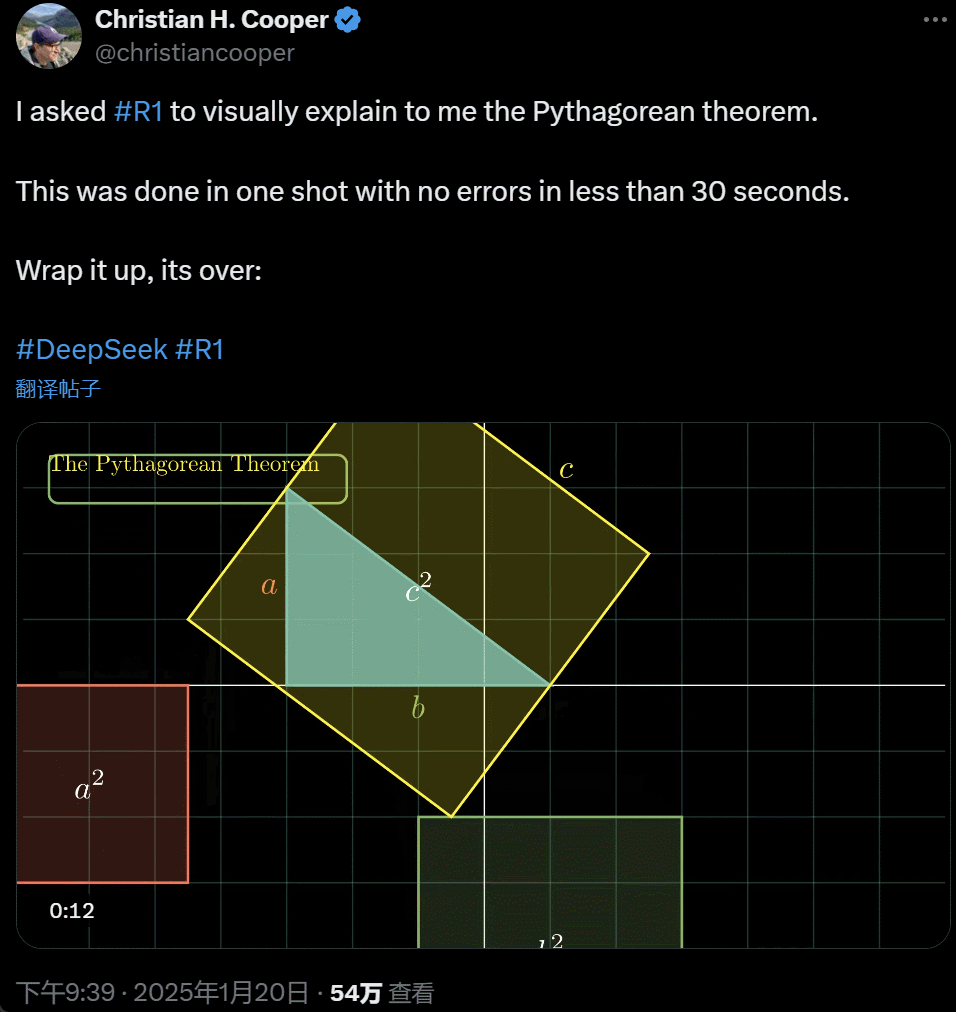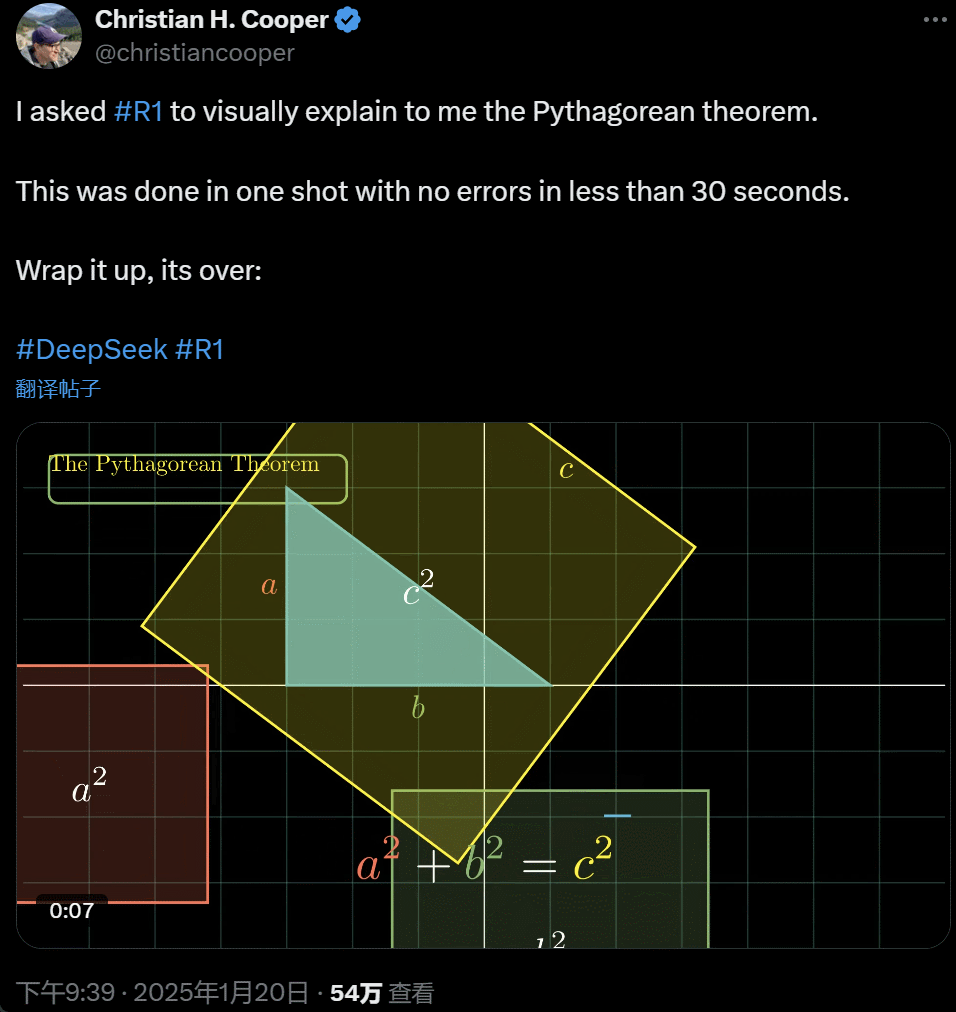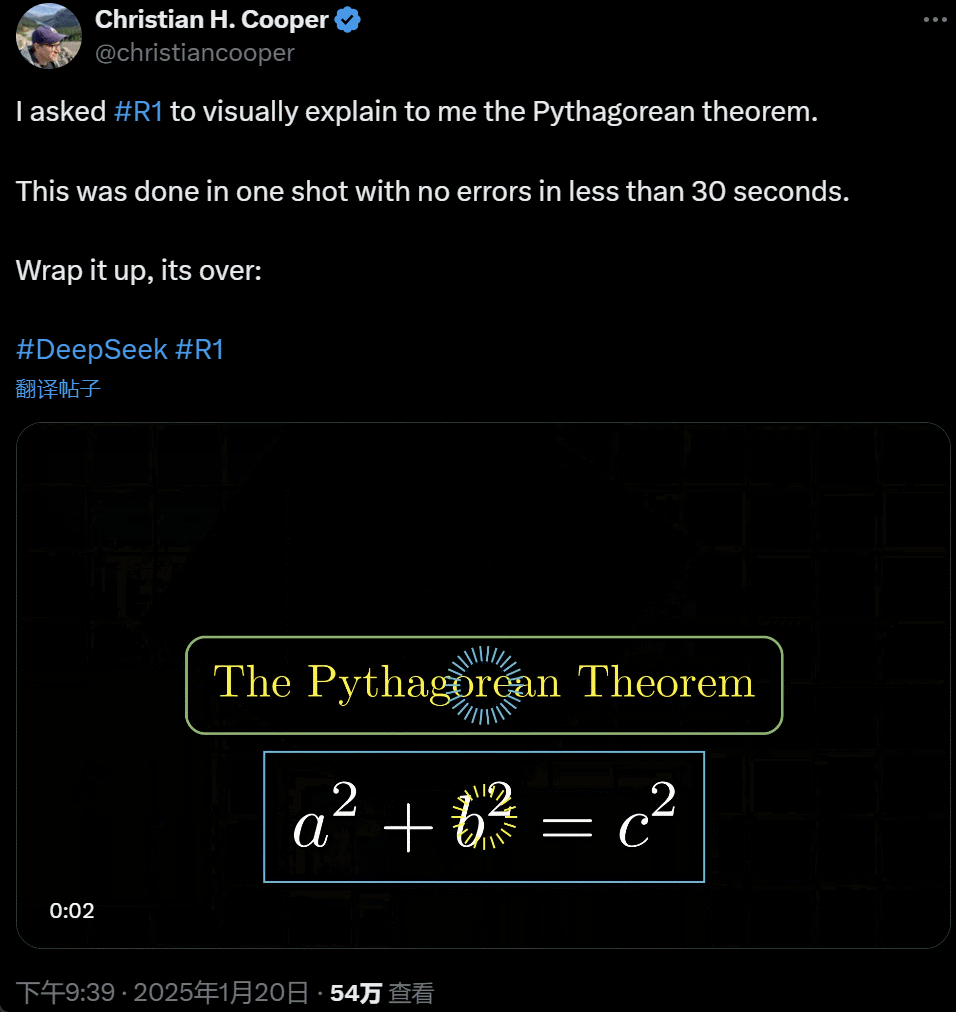
我让 R1 详细解释勾股定理。这一切都是 AI 在不到 30 秒时间里一次性完成的,没出任何错。简单来说,its over.
在国内外 AI 圈,普通网友发现了神奇的强大新 AI(还开源),学界专家纷纷喊出‘要奋起直追’,还有小道消息称海外的 AI 公司已经如临大敌。
就说这个本周刚发布的 DeepSeek R1,它没有任何监督训练的纯强化学习路线令人震撼,从去年 12 月 Deepseek-v3 基座发展到如今堪比 OpenAI o1 的思维链能力,似乎是很快达成的事。
但在 AI 社区热火朝天的读技术报告、对比实测之余,人们还是对 R1 有所怀疑:它除了能跑赢一堆 Benchmark 以外,真的能领先吗?
能自建模拟‘物理规律’
你不信?来让大模型玩玩弹球?
最近几天,AI 社区的一些人开始沉迷一项测试 —— 测试不同的 AI 大模型(尤其是所谓的推理模型)来处理一类问题:‘编写一个 Python 脚本,让一个黄色球在某个形状内弹跳。让该形状缓慢旋转,并确保球停留在形状内。’
一些模型在这项‘旋转球形’基准测试中的表现优于其他模型。据 CoreView CTO Ivan Fioravanti 称,国内人工智能实验室 DeepSeek 的开源大模型 R1 完胜 OpenAI 的 o1 pro 模式,后者作为 OpenAI ChatGPT Pro 计划的一部分,每月收费 200 美元。

左边是 OpenAI o1,右边是 DeepSeek R1。如上所述,这里的 Prompt 是:‘write a python script for a bouncing yellow ball within a square, make sure to handle collision detection properly. make the square slowly rotate. implement it in python. make sure ball stays within the square.’
根据另一位网友在 X 上的说法,Anthropic 的 Claude 3.5 Sonnet 和谷歌的 Gemini 1.5 Pro 模型对物理原理判断错误,导致球偏离了形状。也有用户报告称,谷歌最新的 Gemini 2.0 Flash Thinking Experimental,以及相对更旧的 OpenAI GPT-4o 都一次性通过了评估。
但这里面也是能分出高下的:
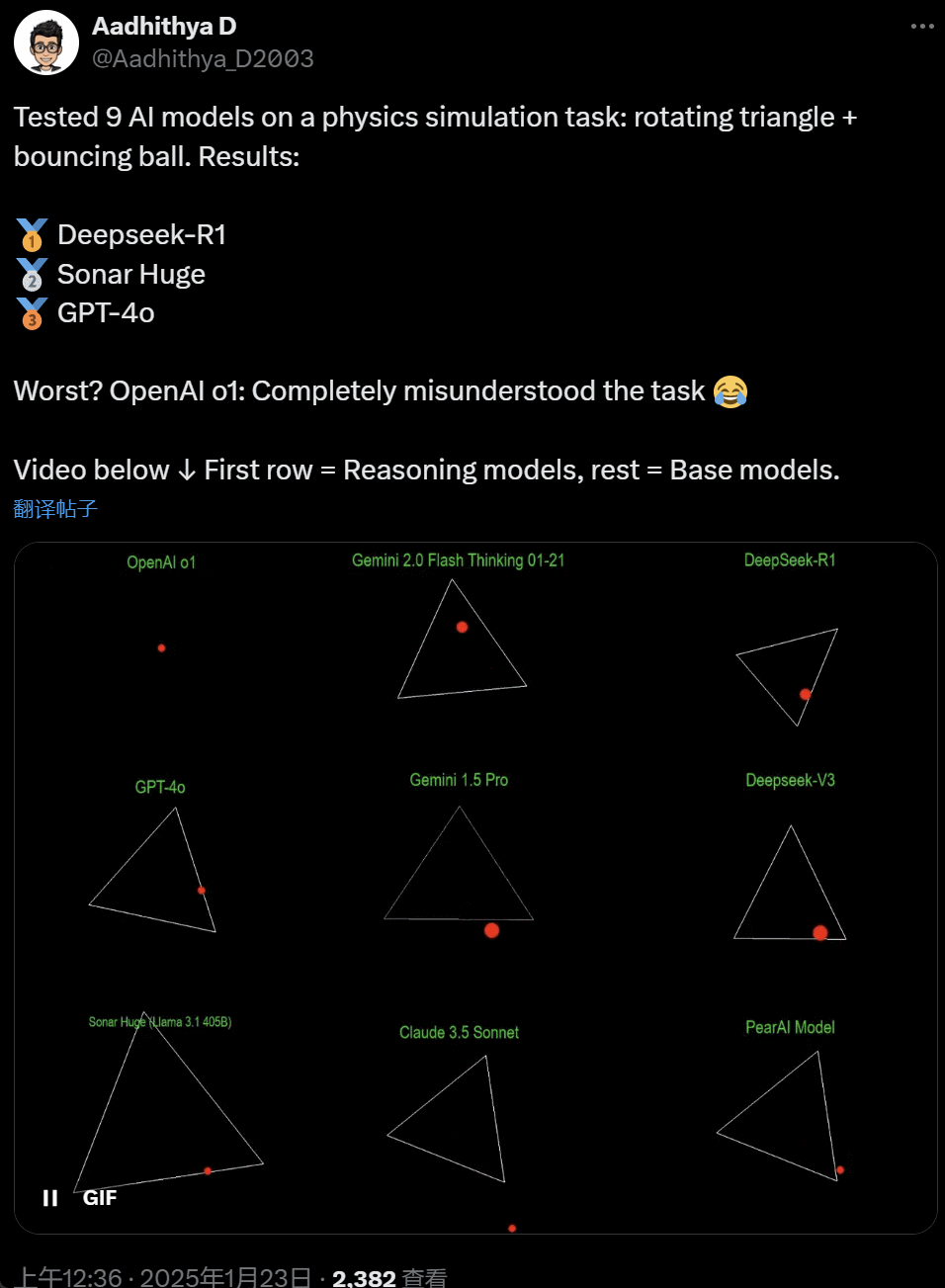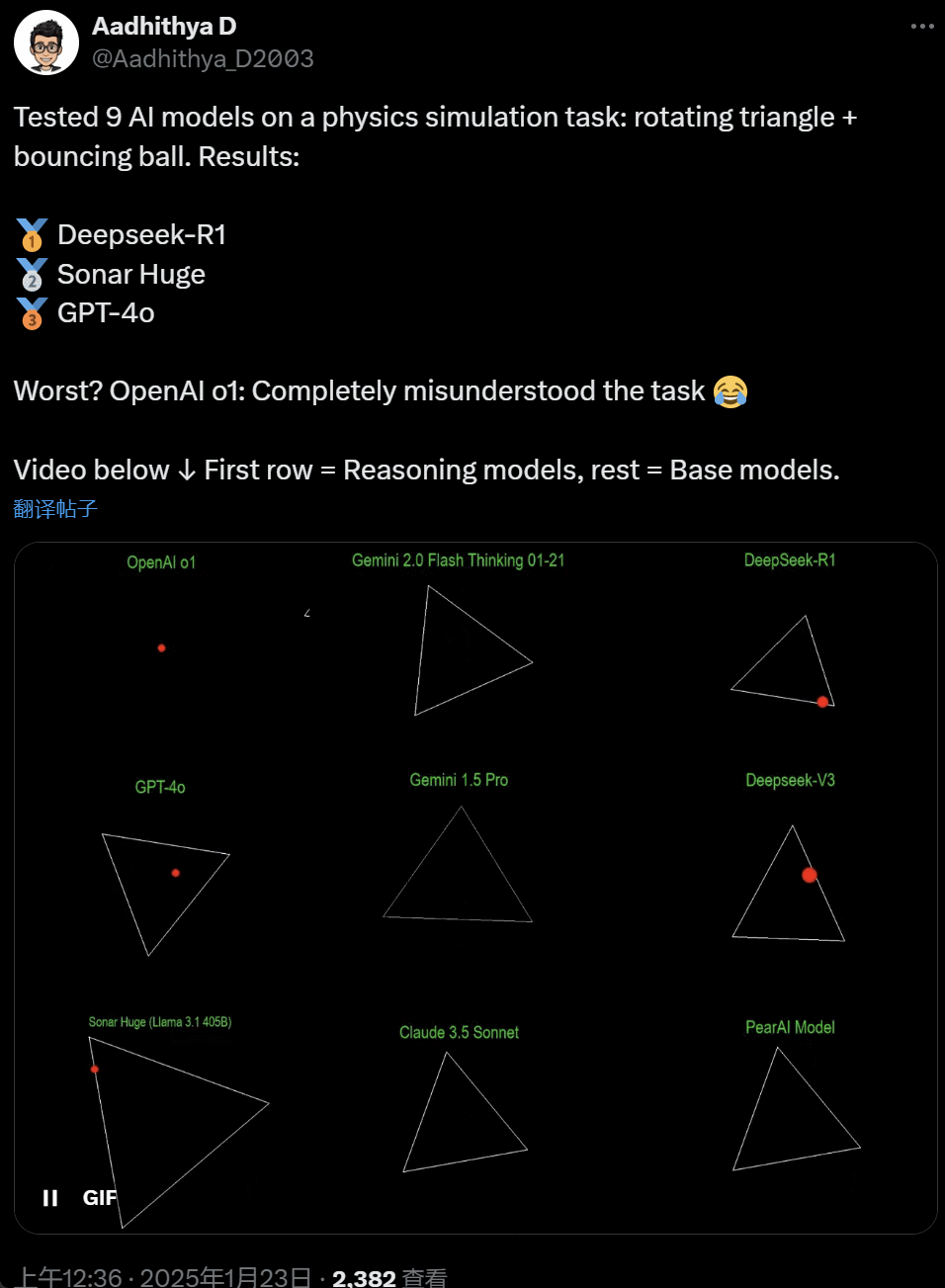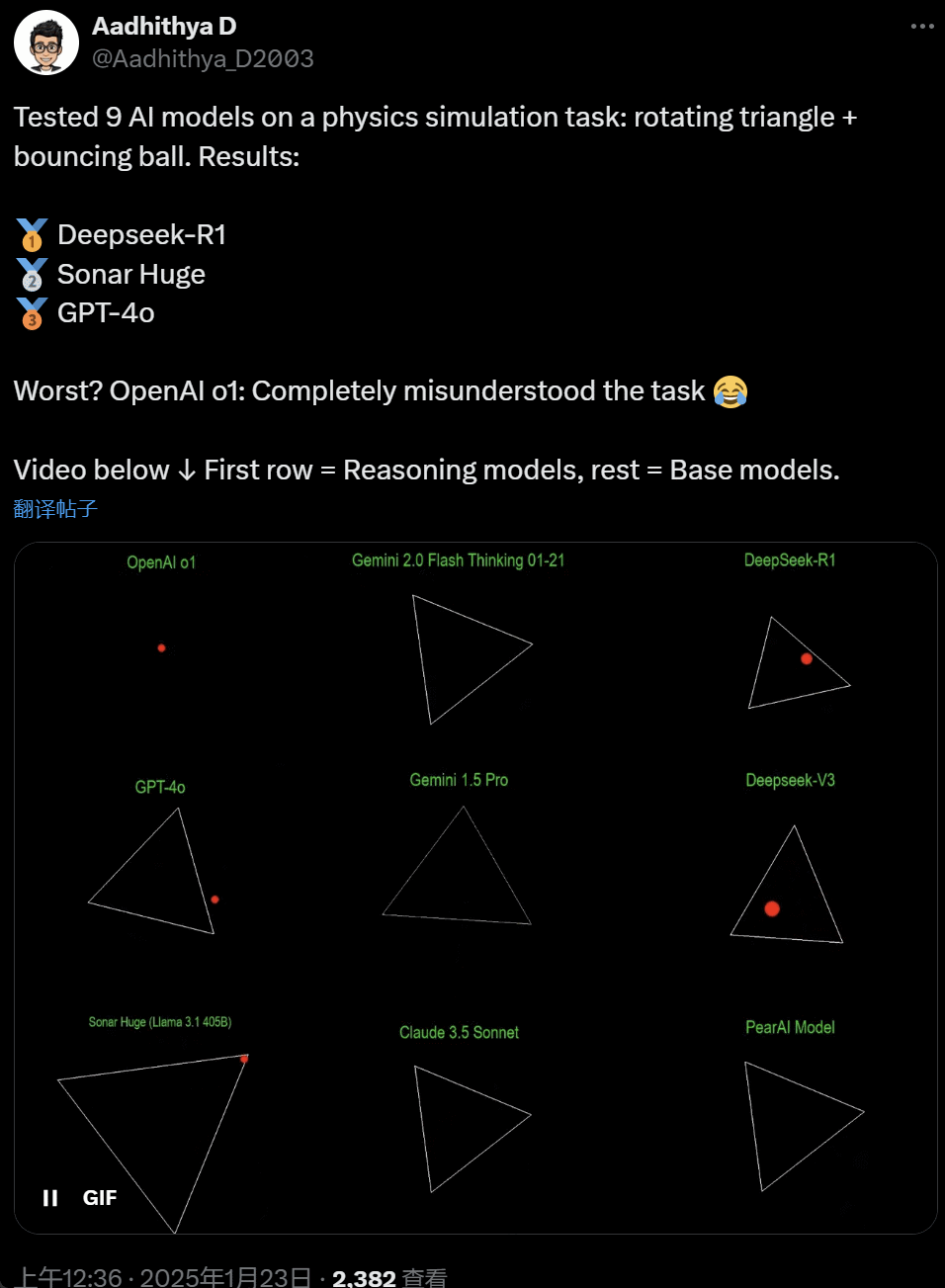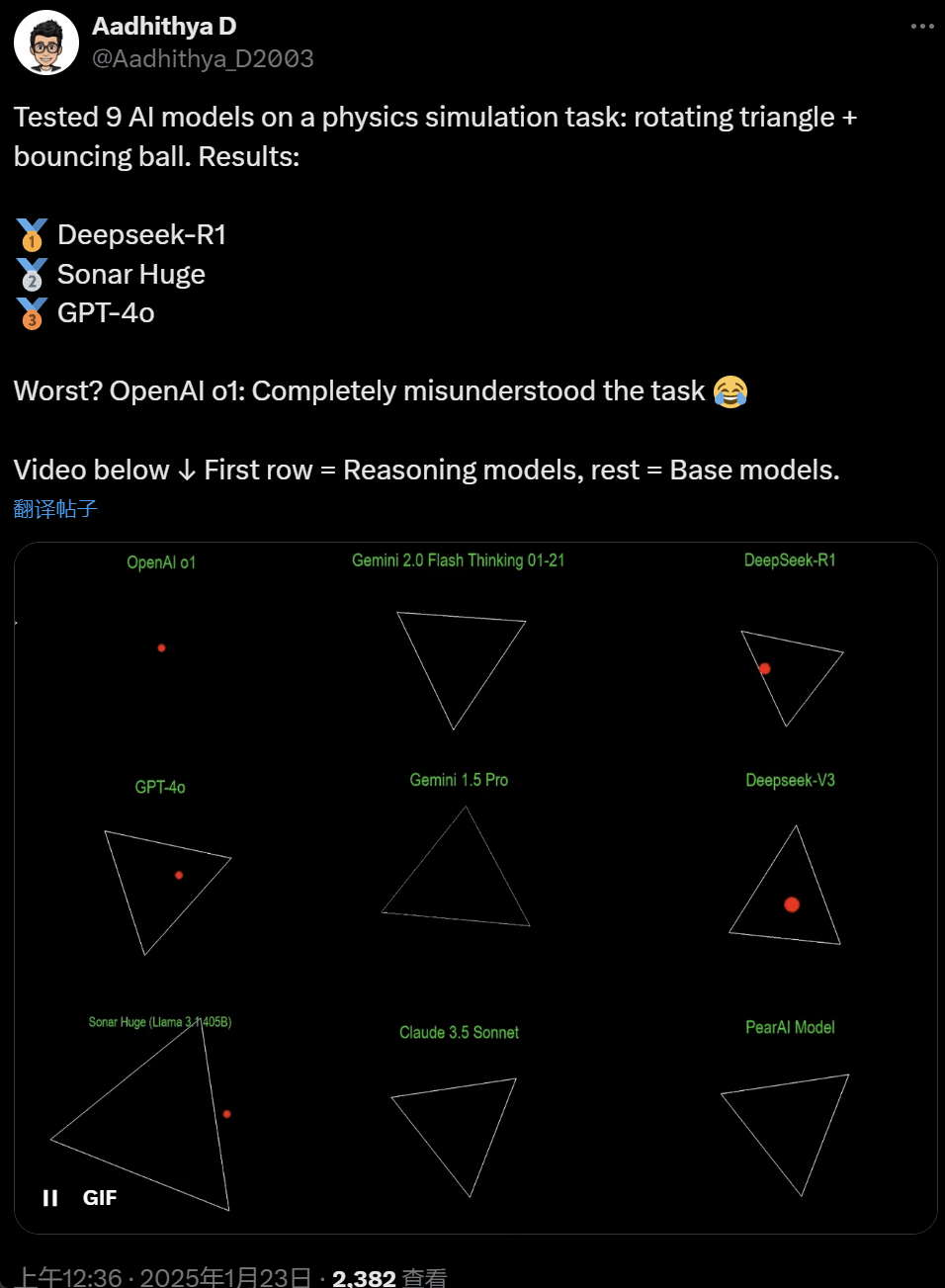
在这个推文底下的网友表示:o1 的能力原本很好,在 OpenAI 优化速度过后就变弱了,即使是每月 200 美元的会员版也一样。
模拟弹跳球是一个经典的编程挑战。精确的模拟结合了碰撞检测算法,其算法需要去识别两个物体(例如一个球和一个形状的侧面)何时发生碰撞。编写不当的算法会影响模拟的性能或导致明显的物理错误。
AI 初创公司 Nous Research 的研究员 N8 Programs 表示,他花了大约两个小时从头开始编写一个旋转七边形中的弹跳球。‘必须跟踪多个坐标系,了解每个系统中的碰撞是如何进行的,并从头设计代码以使其具有鲁棒性。’
虽然弹跳球和旋转形状是对编程技能的合理测试,但对于大模型来说还是个新项目,即使是提示中的细微变化也可能产生出不同的结果。所以如果想让它最终成为 AI 大模型基准测试的一部分的话,还需要改进。
无论如何,经过这一波实测之后,我们对大模型之间的能力不同有了观感。
DeepSeek 是新的‘硅谷神话’
DeepSeek 正让大洋彼岸陷入‘恐慌’。
Meta 员工发帖称‘Meta 工程师们正在疯狂地分析 DeepSeek,试图从中复制任何可能的东西。’
而 AI 科技初创公司 Scale AI 创始人 Alexandr Wang 也公开表示,中国人工智能公司 DeepSeek 的 AI 大模型性能大致与美国最好的模型相当。
他还认为,过去十年来,美国可能一直在人工智能竞赛中领先于中国,但 DeepSeek 的 AI 大模型发布可能会‘改变一切’。
X 博主 @8teAPi 则认为,DeepSeek 并不是一个‘副业项目’,而是像洛克希德・马丁以前的‘臭鼬工厂’。
所谓‘臭鼬工厂’,就是当初洛克希德・马丁公司(Lockheed Martin)为了研发诸多先进飞行器专门成立的一个高度机密、相对独立的小团队,从事尖端或非常规的技术研究与开发。从 U-2 侦察机、SR-71 黑鸟,到 F-22 猛禽、F-35 闪电 II 战斗机都是从这里走出来的。
后来,这个词逐渐演变成一个通用术语,用来形容在大公司或组织内部设立的‘小而精’、相对独立且自由度更高的创新团队。
他给出的理由有两个:
一方面是 DeepSeek 拥有大量的 GPU,据称有超过一万块,而 Scale AI 的 CEO Alexandr Wang 甚至表示可能达到 5 万块。
另一方面,DeepSeek 只从中国排名前三的大学招聘人才,这意味着 DeepSeek 与阿里巴巴和腾讯具有同等的竞争力。
仅凭这两个事实,就可以看出,显然 DeepSeek 在商业上取得了成功,并且已经足够知名,能够获得这些资源。
至于 DeepSeek 的开发成本,该博主表示,中国科技公司可以获得各种各样的补贴,比如低用电成本和用地。
因此,DeepSeek 非常有可能大部分成本都被‘安置’在核心业务之外的某个账目上,或者以某种数据中心建设补贴的形式存在。甚至除了创始人之外,没人完全清楚所有财务安排。有些协议可能只是‘口头协定’,只靠声誉就能敲定。
不管怎样,有几点是明确的:
这个模型非常出色,与 OpenAI 两个月前发布的版本相当,当然也有可能不如 OpenAI 和 Anthropic 尚未发布的新模型。
从目前来看,研究方向仍主要由美国公司主导,DeepSeek 模型属于对 o1 版本的‘快速跟进’,但 DeepSeek 的研发进度非常迅猛,比预期更快地迎头赶上,他们并没有抄袭或作弊,最多只是逆向工程。
DeepSeek 主要是在培养自己的人才,而不是依赖美国培养的博士,这大大扩展了人才库。
与美国公司相比,DeepSeek 在知识产权许可、隐私、安全、政治等方面受到的约束较少,围绕错误地使用那些不想被训练的数据的担忧也较少。诉讼更少,律师更少,也更少顾虑。

毫无疑问,越来越多的人认为 2025 年将会是决定性的一年。与此同时各家公司都在摩拳擦掌,比如 Meta 就正在建立一个 2GW+ 的数据中心,预计在 2025 年投资 600-650 亿美元,年底拥有超过 130 万块 GPU。
Meta 甚至用一张图表展示了 2 千兆瓦数据中心与纽约曼哈顿的对比。
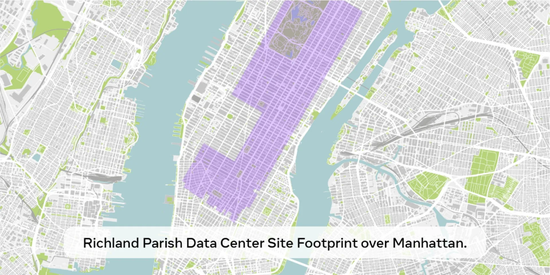
但现在 DeepSeek 用更低的成本,更少的 GPU 做到了更好,怎能不让人焦虑?
Yann LeCun:要感谢开源
Hyperbolic 的 CTO、联合创始人 Yuchen Jin 发帖表示,在仅 4 天时间里,DeepSeek-R1 向我们证明了 4 个事实:
开源 AI 仅落后于闭源 AI 不到 6 个月
中国正在主导开源 AI 竞赛
我们正进入大语言模型强化学习的黄金时代
蒸馏模型非常强大,我们将在手机上运行高智能 AI
由 DeepSeek 引发的连锁反应仍在继续,比如 OpenAI o3-mini 免费可用、社区中希望能减少关于 AGI/ASI 的模糊讨论以及传闻 Meta 陷入恐慌等。
他认为,现在很难预测最终谁会获胜,但不要忘记后发优势的力量,毕竟我们都知道是 Google 发明了 Transformer,而 OpenAI 解锁了其真正潜力。
此外,图灵奖得主、Meta 首席人工智能科学家 Yann LeCun 也表达了自己的看法。
‘对于那些看到 DeepSeek 的性能就认为“中国正在超越美国的 AI”的人,你理解错了。正确的理解是:开源模型正在超越专有模型。’
LeCun 表示,DeepSeek 之所以这次一鸣惊人,是因为他们从开放研究和开源(如 Meta 的 PyTorch 和 Llama)中获益。DeepSeek 提出了新想法,并在他人工作的基础上构建。因为他们的工作是公开发布和开源的,每个人都可以从中受益,这就是开放研究和开源的力量。

网友们的反思还在继续,在对于新技术发展兴奋的同时,也能感受到一点点忧虑的气氛,毕竟 DeepSeek 们的出现,可能会带来真金白银的影响。
参考内容:
https://x.com/ivanfioravanti/status/1881969391547683031
https://x.com/Aadhithya_D2003/status/1882105009548222953
https://x.com/8teAPi/status/1882836551866204656
https://x.com/Yuchenj_UW/status/1882840436974428362
https://x.com/ylecun/status/1882943244679709130
https://venturebeat.com/ai/tech-leaders-respond-to-the-rapid-rise-of-deepseek/
相关文章






热门文章

随着马赫萨·阿米尼逝世两周年的临近,伊朗妇女不再戴头巾
2024-12-16
24年香港正版资料免费公开,2024全年免费资科大全,3网通用:3DM60.01.16
2024-12-1849图库-资料中心,最准一肖精准,移动\电信\联通 通用版:主页版v061.660
2024-12-18246天天天彩天好彩资料大全二四,红姐统一图库图免费第一,移动\电信\联通 通用版:3DM82.61.61
2024-12-18王浩辞去浙江省省长职务
2024-12-1949图库在线预览,二四天天正版资料免费大全,移动\电信\联通 通用版:手机版743.340
2024-12-18
市场专家洞察:4种加密货币准备在2025年牛市中占据主导地位
2024-12-16
Pembina Gas Infrastructure签署4亿美元协议,从Veren购买中游资产
2024-12-16
有话要说...